本周总结
主要工作总结
- 正逆运动学
- EASpace
2023.08.08
欧拉角
欧拉角(Euler angle)指的是绕参考坐标系主轴(x,y,z)之一旋转的角度。
也就是说,若新的坐标系是绕旧的坐标系的主轴(x,y,z)之一旋转形成的,那么这个旋转角就是欧拉角。
旋转矩阵 / 姿态
用标准正交基 $(e^a_1, e^a_2, e^a_3)$ 表示坐标系 $\{a\}$
用 $R_{ab}$ 表示坐标系 $\{b\}$ 相对坐标系 $\{a\}$ 的姿态
坐标系 $\{b\}$ 的标准正交基在坐标系 $\{a\}$ 下的表示为
变换参考坐标系
坐标系姿态参考坐标系的变换
向量参考坐标系的变换
旋转矩阵的正交性
旋转某个向量
一般位姿变换矩阵
也即
基于全局坐标系(固定坐标系)的旋转变换左乘旋转矩阵,基于自身坐标系(动坐标系)的旋转变换右乘旋转矩阵
对于左乘和右乘,可以理解为左乘通常做的是坐标变换,针对的是坐标。右乘做的是基变换,针对的是坐标系
基变换 / 坐标变换
世界坐标系的基(列向量):$e^w_1=(1,0,0)^T$,$e^w_2=(0,1,0)^T$,$e^w_3=(0,0,1)^T$
机体系的基(列向量):$e^b_1$,$e^b_2$,$e^b_3$
坐标系变变换(右乘变换矩阵):$(e^b_1,e^b_2,e^b_3)=(e^w_1,e^w_2,e^w_3)Rot(Z)Rot(Y)Rot(X)$
坐标变换
机体系下表示的向量
将上述向量在世界系下进行表示
将世界系下的向量作与机体系姿态相应的旋转,使得旋转前后的向量在两个坐标系下的表示方法相同
世界系下的一个向量
对向量绕 z, y, x 轴旋转
新向量在机体系下的坐标应与
坐标系
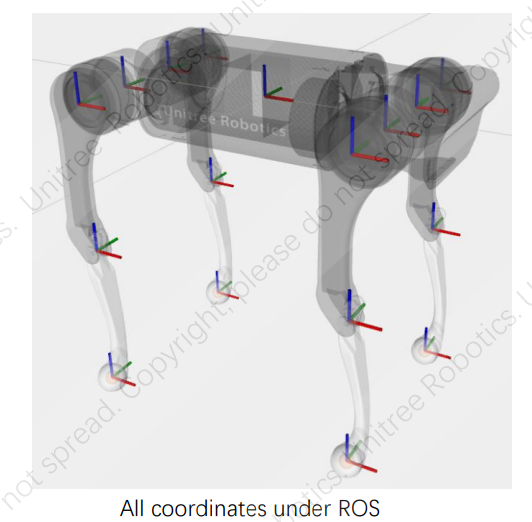
The rotation axis of the hip joint is the x-axis, and the rotation axis of the thigh and calf joints is the y-axis, and the positive rotation direction conforms to the right-hand rule.
机身关节旋转轴为 x 轴,大腿关节和小腿关节的旋转轴为 y 轴,旋转正方向符合右手定则。
The zero points of each coordinate are shown above. Red is the x-axis, green is the y-axis, and blue is the z-axis. Due to the limit of the calf joint, this position cannot actually be reached. It can be seen that the initial posture of each joint coordinate system is the same, but the position and rotation axis are different.
当各个关节均为零度时,各坐标系如上图。红色为 x 轴,绿色为 y 轴,蓝色为 z 轴。小腿关节由于限 位,实际到不了这个位置,这里仅为了指明零点位置。可以看出,各个关节坐标系的初始姿态都是一致的, 只是位置和旋转轴不同。
左侧腿运动学方程
假设各个关节角度为 $\theta_0,\theta_1,\theta_2$,连杆长度分别为 $L_0,L_1,L_2$ ( hip / joint / calf )
$(x_{03},y_{03},z_{03})$ 表示足端相对髋关节的位置
先考虑第 2、3 个关节,足端在大腿关节的表示为
再考虑第 1 个关节,足端在髋关节下的表示为
综上
右侧腿运动学方程
同理
逆运动学
建立运动学方程,描述足端相对机身的位置与各个关节角度之间的关系
Algorithm
给定 $x_d$ 以及正运动学方程 $x = f(\theta)$
初始化 $\theta_0$
While 循环
当 $||e||<\epsilon$ 时结束循环,并获得 $\hat{\theta}_d$
Cyclic Coordinate Descent

1 | for i = 1,…,k do |
Algorithm?
给定序列 $\{x_t\}_{t\in T}$ 以及 $\theta_0$
J 的选取
阻尼最小二乘法
求解上述优化问题得到
冗余雅可比矩阵求逆
雅可比矩阵转置法
2023.08.10
Forward / Inverse Kinematics
- Forward Kinematics Equations for left / right side legs (relative to hip joint / base pos)
- Compute Jacobian
- Inverse Kinematics
Motion Imitation
motion_imitation/motion_imitation/robots at master · erwincoumans/motion_imitation
PyTorch
torch.mul 按元素相乘 *
torch.div 按元素相除 *
torch.square 平方 *)
torch.dot 点乘 *)
torch.sum 求和 *) dim keepdim
交流
2023.08.12
Isaac Gym 迁移
略
精读 EASpace (Enhanced Action Space)
概念
机器学习算法(三十):强化学习 (Reinforcement Learning) | 意念回复的博客
分层强化学习 (hierarchical reinforcement learning, HRL)
以半马尔可夫决策过程 (semi-markov decision process, SMDP)为理论基础,基于分层抽象技术,从结构上对 RL 进行改进,重点关注 RL 难以解决的稀疏奖励、顺序决策和弱迁移能力等问题,实现了更强的探索能力和迁移能力
- 稀疏奖励
- 顺序决策
- 弱迁移能力
基于分层抽象技术,学者们提出了丰富多样的 DHRL 方法,根据求解思路的差异,我们将它们分为:
(1) 基于技能的深度分层强化学习框架 (option-based DHRL, O-DHRL) (option 在 O-DHRL 中常被称为技能(skill),为保证符号的统一,下文依然用符号 o 来表示)。下层网络学习一组技能,然后由上层网络调用这些技能,使用不同的组合技能来解决下游任务
(2) 基于子目标的深度分层强化学习框架 (subgoal-based DHRL, G-DHRL)。利用神经网络提取状态特征,然后将状态特征作为子目标空间。上层网络学习产生子目标,下层网络根据内部驱动来实现子目标
O-DHRL 与 SMDP 密不可分,而求解 SMDP 问题的关键在于如何定义和寻找 option。从内容上看,option 既可以由先验知识定义,也可以由算法学习产生。从形式上看,option 既可以是单步的基础动作,也可以是一组动作序列,或是另一组 option。
【论文笔记】基于分层深度强化学习的移动机器人导航方法 d3qn 论文 | Ctrl+Alt+L 的博客
现有 DRL 导航方法的研究:
- 将导航任务视为避障与目标接近两个子任务的结合
- 分别设计奖励函数, 引导移动机器人在避开障碍的同时接近目标点,但是设计奖励函数需要较多的先验知识
- 在长廊、死角处容易出现局部最小
本文主要工作叙述:
- 采用基于 option-based HDRL 的模型框架
- 通过设计基于规则的目标驱动控制模型和基于 DRL 的避障控制模型, 分别实现目标接近与避障两种低层行为策略
- 利用基于 DRL 的行为选择模型学习稳定、可靠的高层行为选择策略, 有效避免了对人为设计调控规则的依赖
- 在训练避障控制模型的同时训练行为选择模型, 并将接近行为的经验数据也存入避障控制模型的经验池
实际上,分层强化学习解决的是强化学习中的 稀疏奖励(sparse reward)问题:当环境奖励过于稀疏时,智能体可能长期都没有办法获得具有正奖励的样本,给值函数和策略的学习带来了困难。通过分层把策略分为不同层级的子策略,每个子策略在学习的过程中会得到来自上一层级传递来的奖励,这样可以大大提升 样本的利用效率(sample efficiency)。
【分层强化学习】The Option-Critic Architecture 阅读笔记
一个马尔科夫选项(option)
option的存在使得 MDP 变成了 半马尔科夫过程(Semi-Markov Decision Process)
在该设定下,需要解决的问题有:学习option上的价值函数与策略(value function and policy over options)以及学习option内的策略与终止函数(intra-option policies and termination functions)
2023.08.13
Multi-agent reinforcement learning algorithms · Issue #7 · NVIDIA-Omniverse/IsaacGymEnvs