本周总结
主要工作总结
2023.08.14
2023.08.15
因为RL中存在 actor 和 learner,所以 RL 中的串行很显然指的是 actor $\rightarrow$ learner $\rightarrow$ update….这种交替执行的过程,即依次执行动作得到奖励,直到样本数足够训练,然后执行梯度下降并更新网络
而并行在 RL 中的情况较多,大致可以分成 3 种:
- actor 并行,只有一个 learner(同步 update)
- actor-learner 并行(异步 update)
- actor-learner 并行,数据并行分布式训练(同步异步都支持)
2023.08.17
强化学习术语
batch_size
即批大小,如果把全部数据放入内存后再加载到显存中,空间显然不够的;如果一个一个数据加载训练并更新模型参数,效率极低。所以考虑一批一批地加载数据,每次送进去的数量就是batch_size,这样可以加快速度。
用minibatch方法时会定义batch_size,即把整个数据集分几份后,每份的大小就是batch-size。假设把10000个样本,分成500批次送进去,则每次送进20个样本,batch_size=20。
iteration
即迭代,表示每个循环的一遍,一次参数更新。用minibatch时就意味着训练完一个batch。
一个epoch的数据=batch_size * iteration 。假设把10000个样本,分成500批次送进去,则每次送进20个样本,则iteration=500,每经过一个iteration,参数更新一次。
epoch
所有的训练数据都要跑一遍就是一个epoch。假设有10000个样本,这10000个样本都跑完就算一个epoch。实验中一般需要跑很多个epoch,取均值作为最后的结果,一般实验需要训练很多个epoch,取平均值作为最后的结果,从而减少偶然性,避免取到局部极值。
episode
常用于强化学习,以游戏举例,例如模型训练中途或迭代结束后,玩一轮游戏(例如玩一局飞机大战)看看本局游戏能得多少奖励。无论通关还是失败,都是一个episode。如果玩围棋,从头下到尾的一局棋就是一个episode。
SMDP
$S\cross A \rightarrow [0,1]$
视原来的 actions 为 options 的特例
$S\cross O \rightarrow [0,1]$
2023.08.18
强化学习开源框架整理
- 强化学习中的并行方法:ApeX 框架 梯度并行,A3C经验并行 | 分布式异步参数更新,分布式数据生成 | 知乎
- 强化学习开源框架整理
- cleanrl | High-quality single file implementation of Deep Reinforcement Learning algorithms with research-friendly features (PPO, DQN, C51, DDPG, TD3, SAC, PPG)
- Tianshou | An elegant PyTorch deep reinforcement learning library
- EnvPool | C++-based high-performance parallel environment execution engine (vectorized env) for general RL environments
Between MDPs and semi-MDPs: A Framework for Temporal Abstraction in Reinforcement Learning
- options 方法笔记1 | 知乎
- Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning 阅读笔记 | 知乎
HRL
- 【分层强化学习】The Option-Critic Architecture 阅读笔记 | 知乎
- 分层强化学习 survey | 知乎
- 伏羲讲堂 | 分层强化学习 | Intro | 知乎
- 【2 分层强化学习】Option-Critic | 知乎
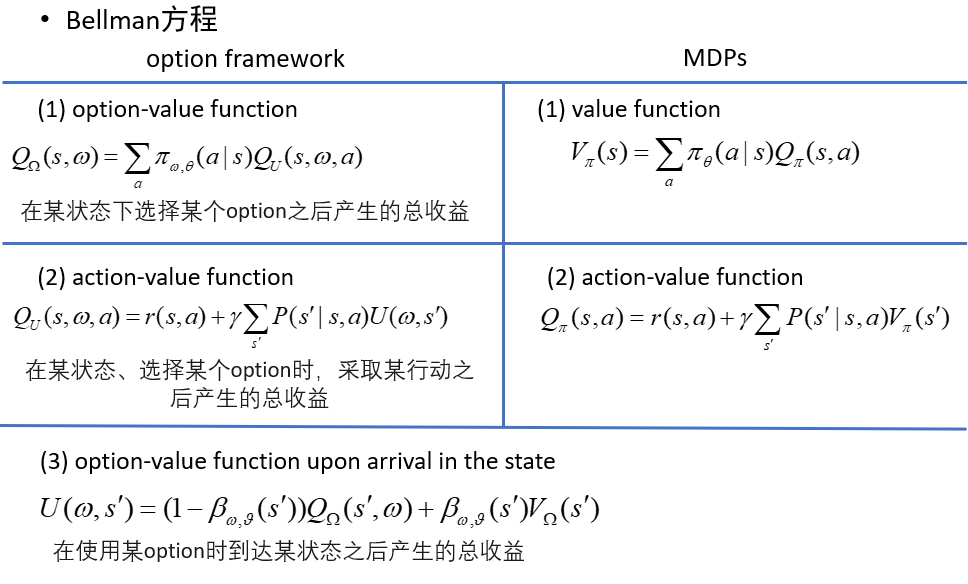
Sutton 论文中给出了 option 框架下的 Bellman 方程,在形式上与一般 MDP 中的 Bellman 方程具有高度统一性
- option-value function:描述的 是在某个状态下选择某个option所能产生的总收益,如果把(s,$\omega$)看成是一个增广状态空间的话,那么就和 MDP 中的 value function 的表现 形式高度一致了
- action-value function:描述的是在某状态,选择了某个 option 的前提下,采取某个 action 所能产生的总收益,和 MDP 的 action-value function 的区别是由于有中断函数的存在,到达下一状态之后的值函数需要综合考虑中断了当前 option 的情况和继续当前 option 的情况,这也是下一个公式所要表达的含义
- option-value function upon arrival in the state:描述的是执行某个 option 之后到达 了下一状态,在新状态下所能产生的总收益,由两种情况综合计算,首先如果继续执行当前 option,即不中断,那么下一状态的价值自然由 option-value function 描述,如果中断了当前 option,而新的 option 还没有选择出来,那么新状态下的价值就只能由 policy over options下新状态的 value function 描述,用以描述选择不同 option 的期望价值
信用分配 Credit Assignment
信用分配是指在复杂学习系统中,如何分配系统内部成员对结果的贡献。例如在监督系统中,分析输入各维度对输出结果的影响,在强化学习系统中,分析动作序列对最终奖励值的贡献,在全局/延迟奖励环境有能加快学习速度,提高样本利用率。
信用分配在强化学习另一个应用是对多智能体强化学习中每个智能体的评价,用于防止 lazy agent
MARL含义:是有多个智能体存在的场景,智能体们可能以合作,竞争或二者兼有的方式完成一个任务(最大化一个全局式累计奖励),要求每个智能体除了考虑到自身观测的状态,还要考虑到其他智能体的动作,策略等信息,以学习到一个使全局累积奖励最大化的策略。